Amid lockdowns and physical distancing mandates to suppress the spread of the Covid-19 pandemic, the internet and various data-driven technologies have proved to be vital lifelines. These technologies provide us avenues to connect with loved ones, receive public health information, telework from home, order meals and groceries, and conduct contact tracing. However, woven into these tech-mediated transactions are countless vulnerable gig workers , delivering your meals and groceries, and filtering social media content to combat misinformation.
Among this vast labor force are the hidden data workers in India, China, Africa and elsewhere who enrich and support the global data-driven technologies that we rely on. However, information and awareness about these data workers are scarce, especially since many are required by clients to sign Non-Disclosure Agreements (NDAs), preventing them from disclosing details about their work.
‘Concealed’ and Alienated From the Global Value Chain
To be sure, NDAs are just one manifestation of the lack of transparency in the global data value chain supporting the development of AI systems and data-driven technologies. A part of the black box (read shadowy) business practices of AI vendors like Amazon, Google, and Microsoft is a reliance on what senior Microsoft researchers Mary L Gray and Siddharth Suri in their 2019 book, Ghost Work term “crowds as code” – a system that turns gig workers into humans-as-a-service. Furthermore, as Trebor Scholz has argued, AI enables “the spectacle of innovation to conceal the worker.”
Behind the top AI vendors’ technological brilliance is an opaque data industry. Google has up to 100,000 temps, vendors, and contracts, including largely hidden data workers, in its two-tiered workforce. One example of this is Google’s secretive RaterHub EWOQ program that continues to use external Search Quality Raters to test the quality of internet content that make its search engine algorithms and optimization possible. Microsoft has its Universal Human Reference System (UHRS), now rebranded as part of Microsoft Azure. Amazon has 500,000 gig workers on its crowdsourcing Amazon Mechanical Turk platform available for its SageMaker suite as part of Amazon Web Services (AWS).
Data workers process and label data to create large data sets used for supervised training of algorithms that order and filter much of our online and offline life.
Their critical role in global data value chain elevates the urgency to shine a light on working conditions of these hidden data workers. The algorithms that run internet search engines and data-driven technologies to detect Covid-19 through audio recordings of coughs are made possible because of hundreds of thousands of hidden data workers. More generally, these workers process and label data to create large data sets used for supervised training of algorithms that order and filter much of our online and offline life. The data extracted from users by AI vendors have no value unless it is processed, fused, and enriched with other data to produce digital intelligence after being put through a data value chain. A part of this value chain is the critical bottleneck of ‘sense-making’ or ‘judgements’ of data by human data workers. This includes tasks like bounding boxes of images, sentiment analysis of social media, transcription from audio, and conducting regular quality assurance and data validation tests.
Despite this painstaking labor, these data workers are alienated and dissociated from the global data value chain. Lakshmi*, who we spoke to in the course of this research, said she does not know “the reason behind this work… we are unaware from beginning and end of the work, nor do we know where it is coming from and how and where that work would be used.”
“We do not know for which company we work [for] but it is known that we work on California. We get data related to California,” said Kuladeep* who works on labeling data for image recognition.
Labor Standards? Need Not Apply
Because of their very invisibility, labor rights and protections as well as social safety nets are unavailable to these workers. AI vendors also exploit the permissive local regulatory contexts and global competition regime that has long permitted and incentivized extractive work conditions and strategies. For example, Indian states like Karnataka and Andhra Pradesh exempt software establishments and the IT and ITeS sectors from the minimum wage provisions as well as other related labor laws.
As a result, workers are both underpaid and made to work long hours. In urban India, data labelers make between Rs 15,000-30,000 a month in starting salary. In rural India, preliminary research shows that data workers are paid on average Rs. 9,300 a month. They reported that their pay was inadequate and did not satisfy their daily needs.
Nipun* who works as a data processing analyst at a firm in rural India, said workers “are not paid enough for how much we are working and are underpaid. A person works for eight hours gets the same salary as some persons working up to 12 hours… I feel it’s unfair.”
Most data work in the global South are in call center-like settings as opposed to stay-at-home work often seen in the global North. This leaves data workers with little option to refuse overtime work that firms invariably demand in order to meet daily production targets.
How the Value Chain Works: Amazon SageMaker’s Humanloop and Crowd Elements
Delving deeper into Amazon SageMaker – a product of the AWS suite – makes clear the link between tech firms’ data value chain and data workers. SageMaker offers clients access to more than 500,000 data workers – a private data labeling workforce connected via third-party vendors to Amazon’s seamless workflow to construct “highly accurate training data sets for machine learning.”
According to the 2020 Amazon SageMaker Developer Guide, data workers are requested on demand through the online crowdsourcing labor platform Amazon Mechanical Turk to build data sets for training AI models and algorithms to power the digital economy. Amazon SageMaker Ground Truth for Labeling uses data workers along with machine learning to create labelled data sets. In SageMaker Ground Truth, raw data is fed into an active learning model trained from human labelled data. Data that the model understands, is automatically labelled. Data that the model cannot accurately recognize and label, is sent to human data workers for triage and annotation. The output is an accurate training data set for supervised machine learning model creation.
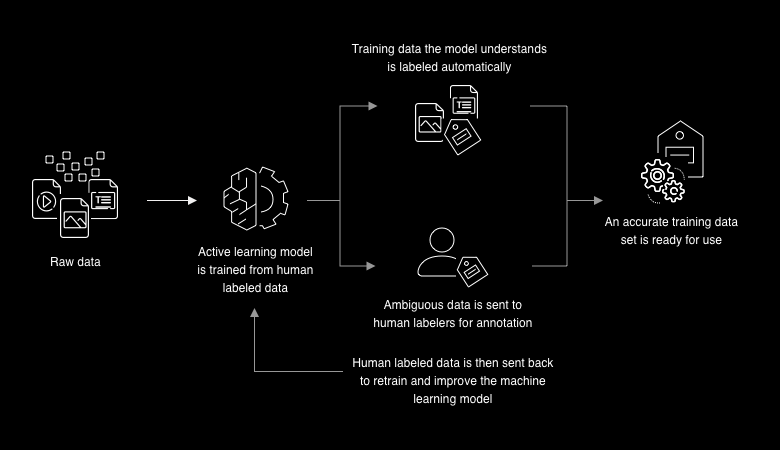
How Amazon’s data labeling service Amazon’s SageMaker Ground Truth works | Amazon SageMaker
To initiate the Amazon SageMaker Ground Truth process, the developer enters the command to request data workers in data labeling workflows through the following crowd elements request HTML syntax:

Another example of ‘crowd as code’ can be seen in Amazon Augmented AI for Human Review (Amazon A2I). It loops in data workers for ‘human-in-the-loop reviews’ to feed and turn a model of low-confidence to one of higher confidence for better predictions and conduct continuous audits for quality control. Low-confidence predictions are sent for human review before they are added to training data sets to improve machine learning models.
The command to request data workers into data review workflows using Amazon A2I is created using Application Programming Interfaces (APIs) by the following humanloop request syntax that starts with:

Organizing Data Workers Behind AI
Amazon SageMaker’s humanloop and crowd elements syntaxes make it undeniably evident that behind some of the most complex data-driven technologies are hundreds of thousands of human workers. Through extractive work conditions and employment relationships, these data workers are virtually dematerialized even as they labor to produce quality data sets needed for machine training models and the maintenance of the internet that we so rely on.
In order to build an AI and data ecosystem that respects human rights, we need to make visible the hidden data workers embedded in the global data value chain linked to some of the world’s biggest tech firms. This calls for including worker’s voices in data governance debates and expanding legal protections to all data workers. This work is currently being undertaken by transnational trade union movements and tech worker solidarity coalitions like Tech Workers Coalition in Bengaluru, Athena – a coalition to stop Amazon’s injustices, Google Walkouts, as well as platform cooperatives. Consumers, developers, and university researchers in Shenzhen, Nairobi, Montreal or the Silicon Valley who use AI vendors like Amazon and other data-driven organizations must also demand greater transparency and hold tech firms accountable.
The Covid-19 pandemic has made visible existing inequalities within the world of work. Measures to suppress the spread of the virus have left countless data workers even more vulnerable than before as work gets put on hold and livelihoods remain suspended. A recovery from this pandemic, cannot just entail a return to the earlier status quo. We need to strive for a better future of work and a fairer global digital economy that works for everyone.
*Names have been changed.
This research was made possible in partnership with IT for Change and with support from Canada’s International Development Research Centre. This article is part of our Labor in the Digital Economy series.